오늘은 결측치 정제에 이어서 이상치 정제에 대해 정리하도록 하겠습니다.

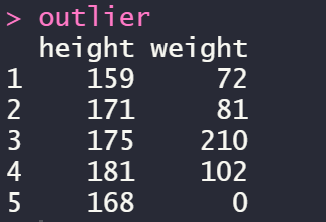
1. 이상치 제거 이상치(outlier)는 정상범위를 크게 벗어난 값을 의미합니다.이상치는 크게 존재할 수 없는 값과 극단적인 값으로 나눌 수 있습니다.이러한 이상치가 포함되어 있으면 분석 결과가 왜곡되기 때문에 데이터 분석에 앞서 이상치를 제거하는 작업이 필요합니다. (1) 존재할 수 없는 값 제거 존재할 수 없는 값이란 예를 들어 남성은 1, 여성은 2의 성별 변수에 3이라는 값이 들어 있는 경우가 이에 해당합니다.1)이상값이 포함된 데이터 생성 성별(sex) 변수는 남성(==1) 또는 여성(==2), 점수 변수는 1점~5점이라는 값이 들어있다고 가정합니다.이때성별변수에3과점수변수에6이라는이상치를넣어보세요.

아웃오브데이터프레임(섹스=c(1,2,1,3,2,1), 스코어=c(5,4,3,4,2,6))기타

결과

네 줄의 성별 변수와 여섯 줄의 점수 변수에 이상치가 생긴 것을 확인할 수 있습니다.2)이상값을 확인하는 raw data가 주어졌을 때 이상값을 확인하기 위해서는 table()을 이용하여 빈도표를 작성하면 됩니다.
테이블 ($sex의 모든 것) ($sex의 모든 것)
결과

성별 변수에 ‘3’이라는 빈도가 1, 점수 변수에 ‘6’이라는 빈도가 1임을 확인할 수 있습니다.3)결측 처리할 이상치의 존재를 파악한 경우 이 이상치를 결측치로 변환하는 과정이 필요합니다. ifelse()를 이용하여 특정 변수의 값이 이상치일 경우 NA를 부여합니다.
기타$ex <-ifelse> (아웃솔 $ex == 3, NA, 아웃솔 $ex) 겉창 $explorer (아웃솔 $explorer > 5, NA, 아웃솔 $explorer) 겉창

결과

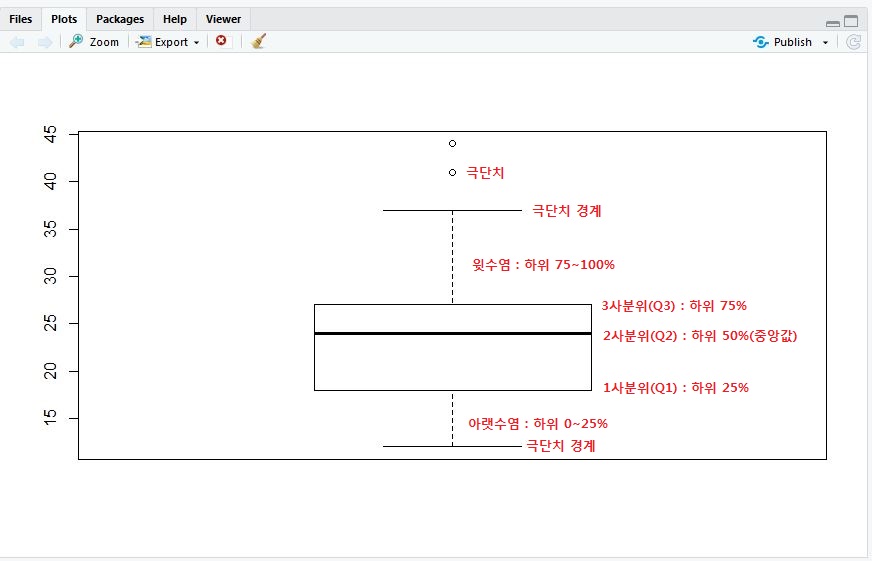
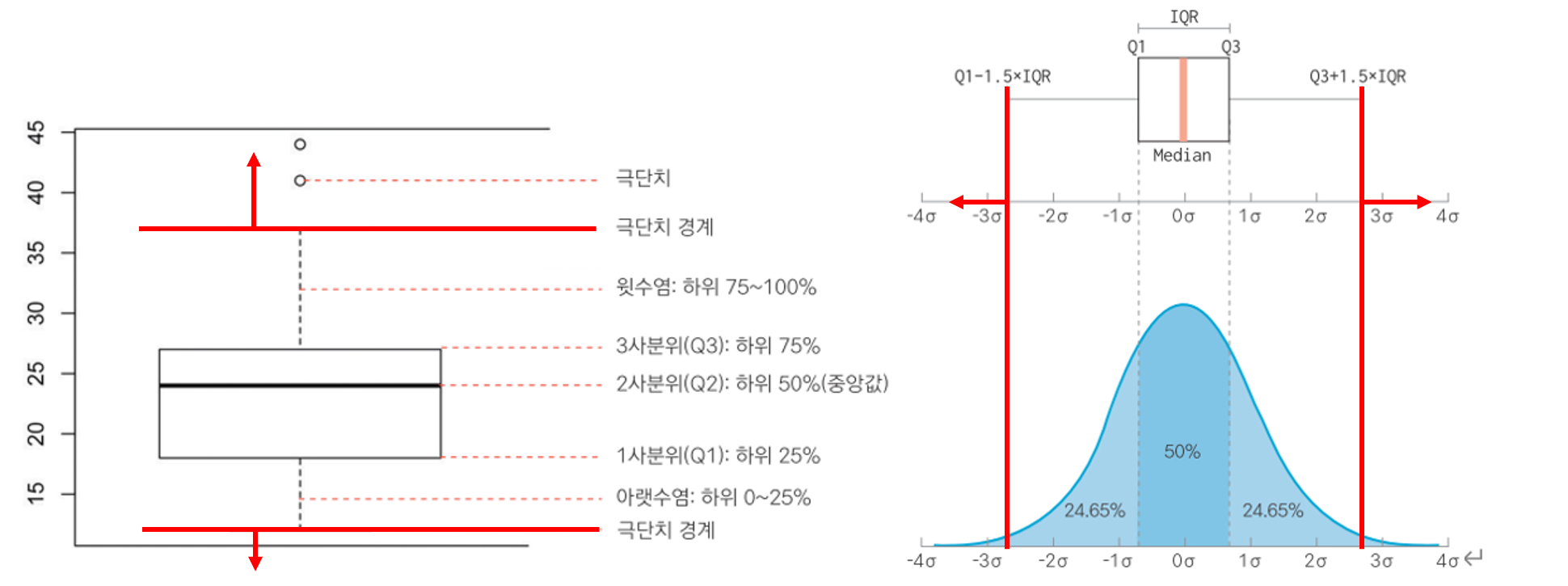
성별 변수와 점수 변수 모두 이상치를 결측치로 변환했기 때문에 데이터 분석이 가능합니다. filter 함수와 is.na()를 이용하여 결측치를 제외하고 group_by()와 summarise()를 이용하여 성별별 점수 평균을 구합니다.outlier%>%filter(!is.na(sex)&!is.na(score))%>%group_by(sex)%>%summaryise(score_score=平均(score))결과※!is.na(), group_by(), summarise()를 잘 모르시면 아래 링크에 자세히 다루었으니 참고해주세요! is.na()R프로그래밍 기초 [5] 결측치 정제(데이터 결측치 제거/is.na/na.rm/na.omit/ 결측치 대체방법) Doit! 쉽게 배우는 R데이터 분석의 6장 내용을 바탕으로 작성한 글입니다. 광고가 아니면 내 돈을 내고… blog.naver.comgroup_by(),summary()R프로그래밍 기초[4] 데이터 가공 2편(집단별요약/ group_by/ summarise/ 데이터 맞추기/ left_join/bind_rows) R프로그래밍 기초 데이터 가공 2편입니다. ↓ 데이터 전처리, 데이터 추출, 데이터 정렬 등의 방법 보기 … blog.naver.comR프로그래밍 기초[4] 데이터 가공 2편(집단별요약/ group_by/ summarise/ 데이터 맞추기/ left_join/bind_rows) R프로그래밍 기초 데이터 가공 2편입니다. ↓ 데이터 전처리, 데이터 추출, 데이터 정렬 등의 방법 보기 … blog.naver.com(2)극단값 극단값이란 논리적으로 존재할 수는 있지만 극단적으로 크거나 작은 값을 의미합니다.그럼 어디까지를 정상 범위로 볼 것인가를 결정하는 것이 중요한 문제입니다. ①논리적 판단 ②통계적 기준 ③boxplot 등의 방법을 이용하여 기준을 정합니다.책에서는 상자 그림을 이용하는 방법을 제시하고 있습니다.1)상자그림에서극단치의기준을정한다,먼저상자그림에대해서살펴보도록하겠습니다.R에서는 아래와 같은 코드에서 상자 그림을 출력할 수 있습니다.박스플롯(mpg$hwy) 박스플롯(mpg$hwy)$플롯$stats 파라미터를 이용하여 통계치를 출력합니다.[1,]가 의미하는 값은 Q0, 즉 아래 극단값의 경계이고, [5,]가 의미하는 값은 Q4, 즉 위 극단값의 경계입니다. 이를 통해 12~37이 넘으면 극단값으로 분류해 결측치(NA)로 변환하는 기준을 세울 수 있습니다.2)결측 처리; 12~37 초과시 NA 할당mpg$hwy = – ifelse(mpg$hwy = 12 + mpg$hwy > 37, NA, mpg$hwy) 테이블(is).na(mpg$hwy)결과결측치(NA)로 분류된 값이 8개임을 알 수 있습니다.이제 이 결측치를 제외하고 분석을 할 수 있습니다. mpg 데이터에서 결측치를 제외하고 drv마다 고속도로 연비(hwy)의 평균을 구해보겠습니다.첫 번째 방법은! is.na 함수를 이용하는 것이고 두 번째는 Na.rm=T를 이용하는 것입니다.summarise 함수는 Na.rm 파라미터가 적용되는 함수임을 기억하세요.mpg%>%filter(!is.na(hwy))%>%group_by(drv)%>%passise(mpg_hwy=平均(hwy))mpg%>%filter(!is.na(hwy))%>%group_by(drv)%>%passise(mpg_hwy=平均(hwy))mpg%>%group_by(drv)%>%dise(mpg_hwy=平均(hwy,na.rm=T))결과이렇게 결측치와 이상치에 대한 내용을 마쳤습니다.다음 게시물부터는 R스튜디오에서 사용할 수 있는 그래프에 대한 내용을 정리해 보겠습니다.#R프로그래밍기초 #R스튜디오 #R #통계분석 #이상보정제 #극단보정제